Heatmap Matrix Explorer
I created a web-based prototype to demonstrate a visualisation technique for analysing pairs of categorical variables.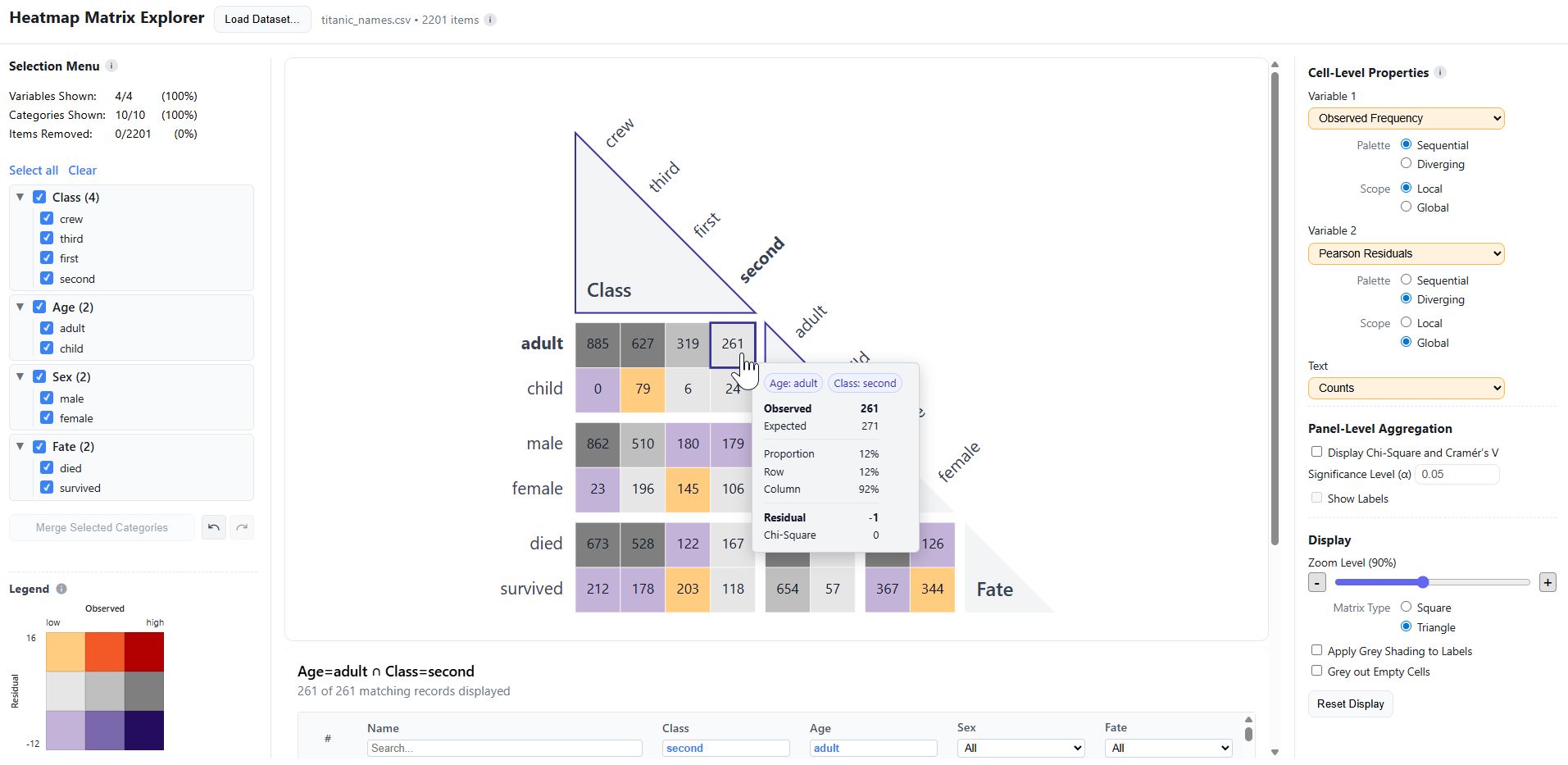

I created a web-based prototype to demonstrate a visualisation technique for analysing pairs of categorical variables.
I designed and implemented a novel technique for visualising multivariate categorical data.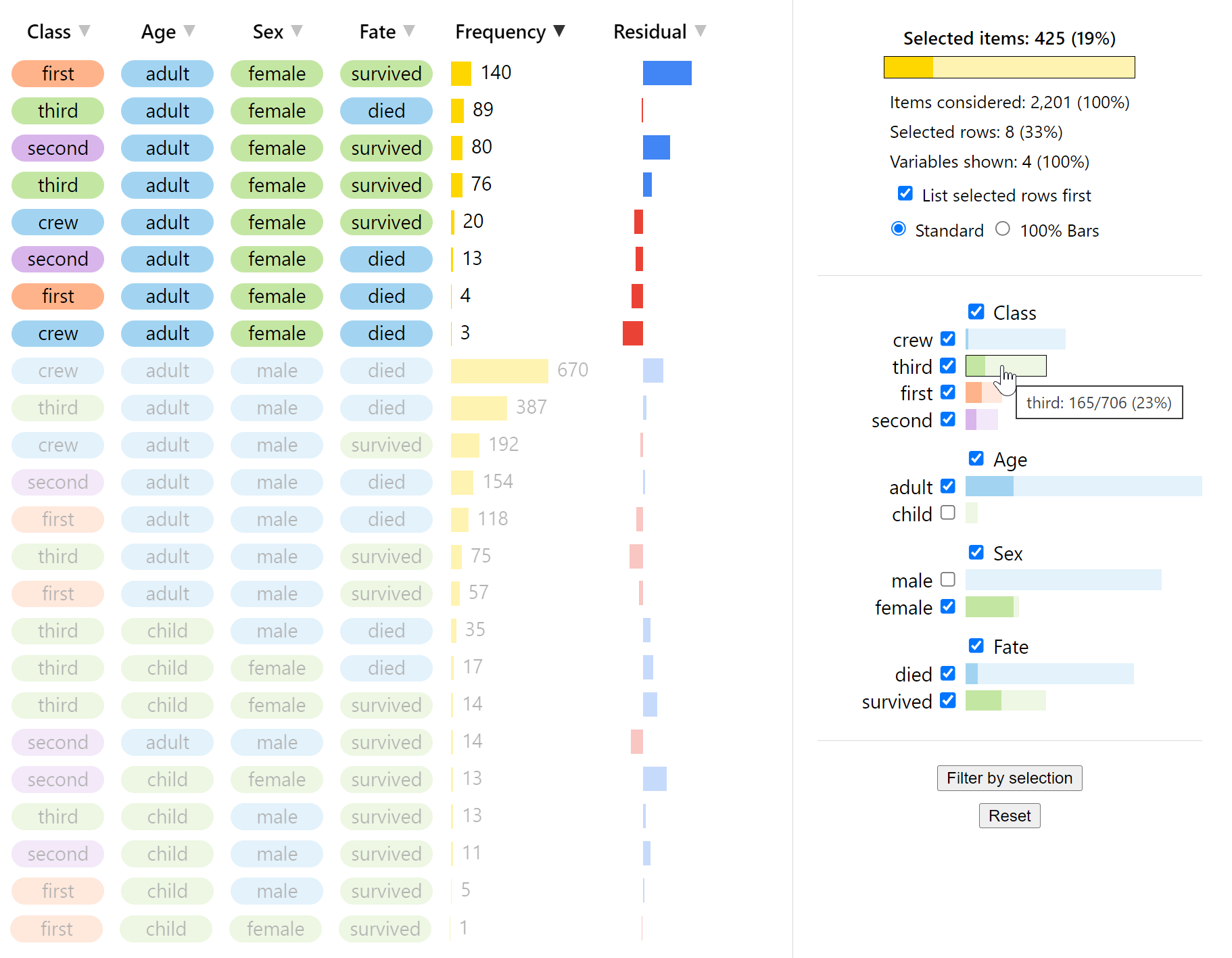
I used computational methods to collect, clean and analyse a corpus of (NZ) English tweets containing Māori loanwords.
Published in 57th Annual Meeting of the Association for Computational Linguistics, 2019
Quick links: paper, poster, data, code
Recommended citation: Trye, D., Calude, A. S., Bravo-Marquez, F., & Keegan, T. T. (2019). Māori loanwords: A corpus of New Zealand English tweets. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, pp. 136-142. Florence, Italy: Association for Computational Linguistics. http://doi.org/10.18653/v1/P19-2018
Published in Frontiers Special Issue in Computational Sociolinguistics, 2020
Quick links: paper, data, code
Recommended citation: Trye, D., Calude, A. S., Bravo-Marquez, F., & Keegan, T. T. (2020). Hybrid hashtags: #YouKnowYoureAKiwiWhen your tweet contains Māori and English. Frontiers Special Issue in Computational Sociolinguistics, 3. https://doi.org/10.3389/frai.2020.00015
Published in Language Resources and Evaluation, 2022
Quick links: paper, data, code
Recommended citation: Trye, D., Keegan, T. T., Mato, P., Apperley, M. (2022). Harnessing Indigenous Tweets: The Reo Māori Twitter corpus. In Lang Resources & Evaluation, 56, 1229-1268. https://doi.org/10.1007/s10579-022-09580-w
Published in Findings of the Association for Computational Linguistics: AACL-IJCNLP, 2022
Quick links: paper, video, code, slides, MET Corpus Explorer, Interactive Error Analysis
Recommended citation: Trye, D., Yogarajan, V., König, J., Keegan, T. T., Bainbridge, D., & Apperley, M. (2022). A hybrid architecture for labelling bilingual Māori-English tweets. In Findings of the Association for Computational Linguistics: AACL-IJCNLP 2022, pp. 119-130. https://aclanthology.org/2022.findings-aacl.11/
Published in International Journal of Corpus Linguistics, 2023
Quick links: accepted manuscript, code
Recommended citation: Trye, D., Calude, A. S., Keegan, T. T., & Falconer, J. (2023). When loanwords are not lone words: Using networks and hypergraphs to explore Māori loanwords in New Zealand English. International Journal of Corpus Linguistics, 28(4), 461-499. https://doi.org/10.1075/ijcl.21124.try
Published in Discourse, Context & Media, 2023
Recommended citation: Calude, A. S., Anderson, A., & Trye, D. (2023). Intensifying expletive constructions and their use on social media: Innovative functions of the hashtag #wokeAF in English tweets. Discourse, Context & Media, 56. https://doi.org/10.1016/j.dcm.2023.100741
Published in 27th International Conference on Information Visualisation (IV), 2023
Quick links: paper, prototype, video, slides
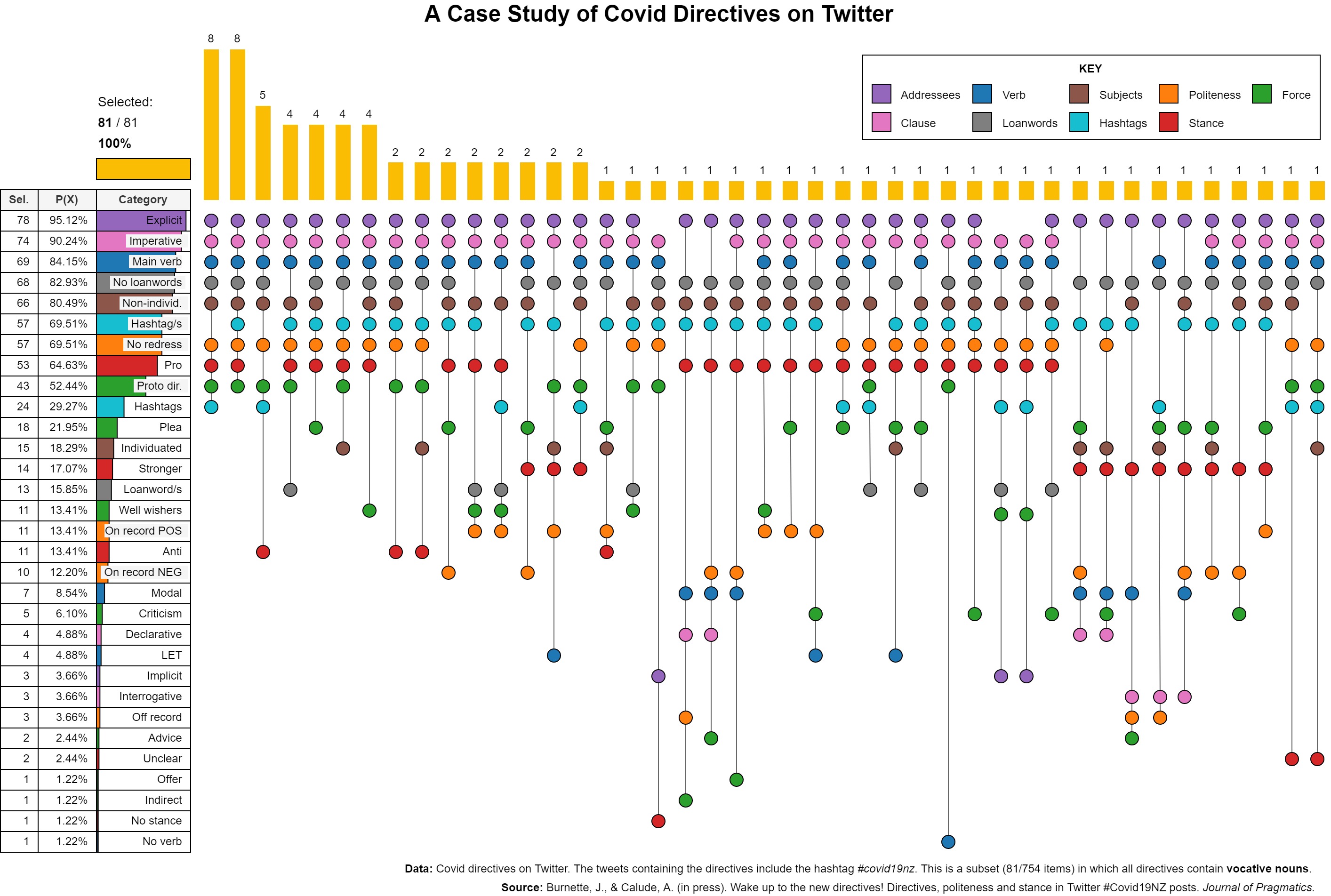
Recommended citation: Trye, D., Apperley, M., & Bainbridge, D. (2023). Extending the Heatmap Matrix: Pairwise analysis of multivariate categorical data. In 2023 27th International Conference Information Visualisation (IV), pp. 29-36. Tampere, Finland: IEEE. https://doi.org/10.1109/IV60283.2023.00016
Published in Languages, 2024
Quick links: paper, supplementary material
Recommended citation: Trye, D., Calude, A. S., Harlow, R., & Keegan, T. T. (2024). Analysing A/O possession in Māori-language tweets. Languages, 9(8), 271. https://doi.org/10.3390/languages9080271
Published in Waikato Research Commons, 2024
Quick links: PhD thesis, CatVis database, Heatmap Matrix Explorer, MultiCat
Recommended citation: Trye, D. (2024). Visualising categorical data: Linguistic case studies from te Reo Māori and New Zealand English. (Doctoral thesis, The University of Waikato, Hamilton, New Zealand). The University of Waikato. https://hdl.handle.net/10289/17049
Published in The Routledge Handbook of Language and Social Media around the World, 2026
Quick links: chapter
Recommended citation: Calude, A. S., & Trye, D. (2026). Language contact phenomena on social media: Perspectives from te Reo Māori and New Zealand English. In The Routledge Handbook of Language and Social Media around the World (pp. 391-404). Routledge. https://www.taylorfrancis.com/chapters/edit/10.4324/9781003360339-32/language-contact-phenomena-social-media-andreea-calude-david-trye
Published:
Quick links: slides
Published:
Quick links: slides
Published:
Quick links: slides
Published:
Published:
Quick links: slides
Published:
Quick links: slides
Published:
Published:
Quick links: paper, poster, preview video, supplementary figure
Published:
Published:
Quick links: slides
Published:
Quick links: slides
Published:
Quick links: video
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.
{kind=link}